
分布式MapReduce。它是一个编程模型和与之关联的运行框架,专门为在大型分布式集群(成千上万台机器)上高效、可靠地处理海量数据(TB/PB级别)而设计。
它的核心思想源于函数式编程中的 map 和 reduce 操作,但将其扩展到分布式环境,并自动处理了分布式计算中复杂的细节(如并行化、任务调度、容错、数据分布、负载均衡、网络通信等),使得开发者只需关注业务逻辑本身。
核心思想
Map
Map 阶段:
- 输入: 处理原始的输入数据块(例如,HDFS 上的文件块)。
- 操作: 由用户定义的
Map函数处理。该函数接收一个 键值对(key1, value1)作为输入。 - 输出: 产生一组 中间键值对
(key2, intermediate_value2)。Map函数对每个输入记录独立执行,互不干扰。 - 并行性: 输入数据被切分成多个分片。每个分片由一个 Map 任务 处理。大量 Map 任务可以并行运行在整个集群的不同节点上(数据本地性优先)。
- 目标: 将原始数据转换和过滤为中间形式,为后续的聚合做准备。
Reduce
Reduce 阶段:
- 输入: 所有 Map 任务产生的、具有相同中间键
(key2)的intermediate_value2会被收集到一起,分组传递给同一个 Reduce 任务。 - 操作: 由用户定义的
Reduce函数处理。该函数接收一个 中间键(key2)和与该键关联的所有中间值的迭代器[intermediate_value2, ...]作为输入。 - 输出: 产生一组最终的结果键值对
(key2, aggregated_value)(通常是零个、一个或多个)。 - 并行性: 不同的中间键
key2被分配到不同的 Reduce 任务。多个 Reduce 任务可以并行运行。 - 目标: 对中间结果进行汇总、聚合、排序或计算,生成最终结果。
Shuffle & Sort
在 Map 阶段后,Reduce 阶段前。
- Shuffle: 系统负责将所有 Map 任务输出的中间键值对,根据中间键
key2通过网络传输(Shuffle)到正确的 Reduce 任务所在的节点。同一个key2的所有值必须发送到同一个 Reduce 任务。 - Sort: 在数据到达 Reduce 任务节点后,系统(通常在 Reduce 任务开始处理前)会按键
key2对接收到的所有中间值进行排序。这使得具有相同键的值在传递给Reduce函数时是连续的,方便迭代处理。
Shuffle & Sort 是 MapReduce 分布式并行化的核心保障,也是性能瓶颈所在(涉及大量网络 I/O 和磁盘 I/O)。
框架职责
任务调度
- 将计算任务(Map Task, Reduce Task)调度到集群中可用的工作节点上执行。
- 优先考虑数据本地性:尽量将 Map 任务调度到存储其所需输入数据块的节点上执行,避免昂贵的网络传输。
故障容忍
- 任务失败: 监控任务执行。如果一个 Map 或 Reduce 任务失败(节点宕机、进程崩溃等),框架会自动在另一个节点上重新调度该任务。
- 主节点失败: (如 Hadoop 的 JobTracker)通常需要外部机制(如 ZooKeeper)或新版框架(如 YARN)的高可用方案。
- 推测执行: 当某个任务运行异常缓慢时,框架可能会在另一个节点上启动一个相同的“推测任务”(Speculative Task)。哪个任务先完成就用哪个的结果,防止“慢节点”拖慢整个作业。
数据传输
- 管理输入数据从分布式文件系统(如 HDFS)读取。
- 高效处理 Map 和 Reduce 任务之间庞大的中间数据(Shuffle)。
- 将最终结果写回分布式文件系统。
负载均衡
- 尽量均匀地将输入数据分片分配给 Map 任务。
- 尽量均匀地将中间键空间分配给 Reduce 任务(避免某个 Reduce 任务处理过多数据)。
状态监控
- 提供接口或 UI 供用户查看作业执行进度、任务状态、计数器等。
工作流程
- 分布式文件系统(HDFS)初始化。
- Map Task 从 HDFS 读取其分配的输入分片, 调用用户
Map函数,处理每条输入记录(key1, value1),输出中间键值对(key2, value2)。输出先写入本地磁盘(避免占用网络带宽)。这些输出被分区(根据 Reduce 任务数量分区)并按键排序。 - 所有 Map 结束后,Reduce Task 主动从所有 Map Task 所在节点的磁盘上拉取属于自己分区的、已排序的中间数据(Shuffle)。将拉取到的来自不同 Map Task 的数据按键进行合并排序(Merge Sort)。
- Reduce Task 调用用户
Reduce函数生最终结果(key2, aggregated_value)。将最终结果写入 HDFS。
原论文执行流程概览:
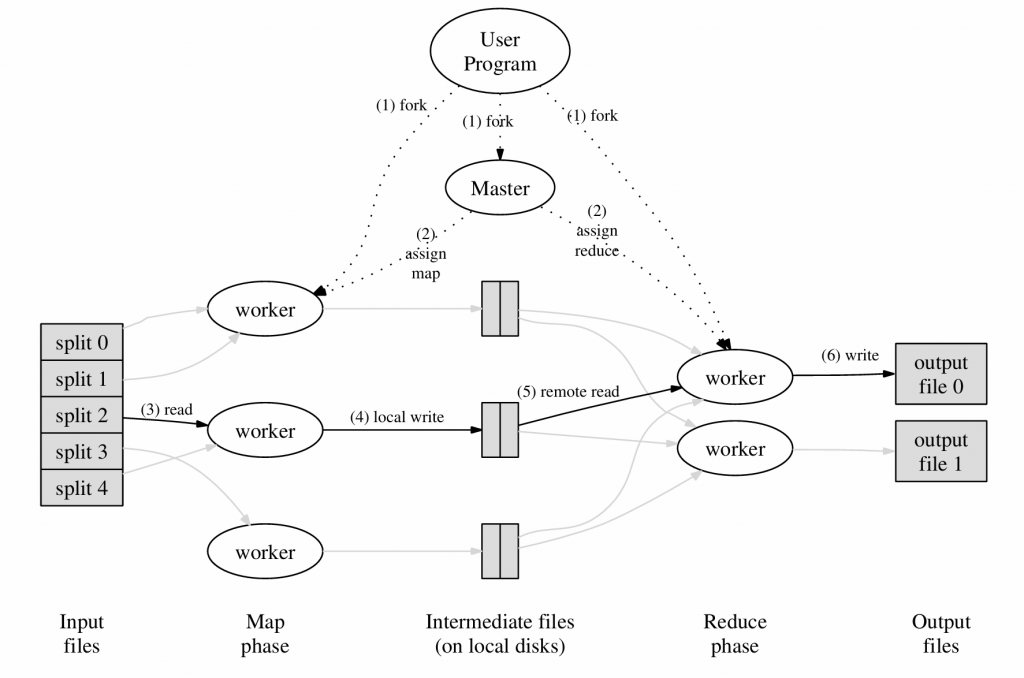
为什么需要排序两次(Map 后一次,Reduce 前一次),而不是Reduce 前一次?
- 降低Shuffle阶段的网络开销
- 问题: 如果Map输出完全不排序,所有具有相同Key的中间键值对
(key2, value2)会随机分散在各个Map任务产生的输出文件中。 - 后果: 当Reduce任务需要拉取属于自己分区(即特定Key范围)的数据时,它必须连接所有Map节点,并从每个Map节点拉取整个属于该分区的数据块。即使某个Key只在少数几个Map任务中出现,Reduce任务也必须检查所有Map输出。
- 优化: Map端按Key排序后,属于同一个Reduce分区的所有Key会连续存储在Map的输出文件中(通常一个文件对应一个分区,或者文件内部按分区排序)。这样,Reduce任务只需要向每个Map节点发起一次请求,就能高效地拉取整个属于自己分区的、已排序的数据块。大大减少了网络连接次数和请求开销。
- 问题: 如果Map输出完全不排序,所有具有相同Key的中间键值对
- 使Reduce端的归并排序(Merge Sort)成为可能
- 问题: Reduce任务需要处理来自所有Map任务的、属于自己分区的数据。最终需要得到一个按Key全局排序的输入流。
- 优化: 如果每个Map任务输出的、发送给特定Reduce任务的数据块
(key2, value2)已经在本地按键排序好了,那么Reduce任务只需要对这些已预排序的多个数据块执行一次高效的归并排序即可。归并排序在处理多个已排序输入流时效率极高(时间复杂度接近 O(n))。 - 对比: 如果Map输出未排序,Reduce端就需要对海量的、完全无序的数据进行一次全排序。全排序(例如使用快速排序)的计算复杂度是 O(n log n),在数据量极大时,这比归并排序慢得多,消耗的资源也多得多。
- 支持Combiner优化
- Combiner是什么? 一个可选的、运行在Map节点本地的“迷你Reduce”函数。它用于在Map输出发送到网络之前,对相同Key的Value进行局部聚合(例如WordCount中,把同一个Map任务里多次出现的
(word, 1)合并成(word, count))。 - 依赖排序: Combiner要高效工作,通常需要Map输出按Key排序(或至少按Key分组)。这样,相同Key的键值对才能连续出现,Combiner才能方便地处理它们。
- 好处: Combiner显著减少了需要通过网络Shuffle到Reduce端的数据量,降低了网络带宽压力和Reduce端的负载。没有Map端排序,Combiner难以有效应用。
- Combiner是什么? 一个可选的、运行在Map节点本地的“迷你Reduce”函数。它用于在Map输出发送到网络之前,对相同Key的Value进行局部聚合(例如WordCount中,把同一个Map任务里多次出现的
- 提高Reduce处理效率
- 问题: Reduce函数
reduce(key2, Iterable)需要处理一个Key对应的所有Value的迭代器。如果输入是按键排序的,那么:- 框架可以很容易地识别出Key的变化(当一个新Key出现时)。
- 相同Key的Value连续到达,可以直接放入迭代器进行处理。
- 对比: 如果输入完全无序,Reduce任务就需要在内存或磁盘上维护一个巨大的哈希表或索引来跟踪所有Key及其对应的Value列表。这会消耗巨大的内存,并且在Key空间很大时极易导致内存溢出(OOM)。对于海量数据,这种方式完全不现实。排序保证了相同Key的数据物理上连续,处理完一个Key就可以释放其资源。
- 问题: Reduce函数
- 优化本地磁盘写入
- Map任务将输出写入本地磁盘(而不是直接通过网络发送,以避免网络拥塞和容错问题)。
- 将数据按键排序后再写入磁盘,比乱序写入通常更高效。操作系统和文件系统对顺序写入的优化远好于随机写入。
容错机制
容错设计
- 任务原子性与幂等性:
- 原子性: Map 任务和 Reduce 任务被视为原子操作。一个任务要么成功完成并产生有效输出,要么完全失败(不产生或只产生无效的中间输出)。
- 幂等性: Map 和 Reduce 函数被设计成幂等的。这意味着对相同的输入数据重复执行相同的任务,总是会产生相同的输出结果。这是容错重试的基础。
- 无状态设计:
- MapReduce 框架本身尽可能保持无状态。任务的状态(输入位置、进度、输出位置)由主节点管理。
- 任务的输出存储是容错的关键点:
- Map 输出: 存储在运行 Map 任务的 Worker 节点的本地磁盘上。位置信息汇报给主节点。
- Reduce 输出: 直接写入高可靠、多副本的分布式文件系统(如 HDFS)。一旦写入成功,数据即持久化且安全。
- 主节点监控:
- 主节点负责监控所有 Worker 节点的状态和所有任务(Map Task, Reduce Task)的执行进度。
Worker 故障
主节点通过心跳机制定期(如每几秒)与所有 Worker 节点通信。如果一个 Worker 节点在预设的超时时间内(如几分钟)没有发送心跳,主节点将其标记为 FAILED。
- 终止该节点上运行的所有任务。
- 重新调度受影响的任务。
由于 Map 任务的输出存储在故障节点的本地磁盘上,该节点宕机后,这些输出不可访问。即使有些任务已完成,也必须重新执行以重新生成其输出供 Reduce 阶段使用。Reduce 任务如果还未将其输出写入 HDFS,也需要重新执行。更加极端的例子:Reduce 失败,且 Reduce 所需的数据也丢失,这时候相关的 Map 和 Reduce 都需要重新运行,会极大的增加任务延迟。
主节点故障
主节点是单点。如果它崩溃,整个集群的作业调度和监控将瘫痪,所有正在运行的作业都会失败。
- 将状态信息定期持久化,配置备用主节点。
应用场景
- 大规模日志分析: 统计访问量、错误日志聚合、用户行为分析。
- Web 索引构建: 倒排索引生成(搜索引擎的核心)。
- 数据仓库 ETL: 从原始数据提取、转换、加载到数据仓库。
- 文档处理/分析: 词频统计(Word Count)、链接分析、模式识别。
- 分布式排序: 利用其内置的排序能力。
- 机器学习(部分): 某些可分解的算法(如朴素贝叶斯训练)。
Comments NOTHING